Bases de données : l’incontournable de la veille stratégique

L’utilité des bases de données dans un corpus de sources
La veille stratégique s’effectue à partir d’un ensemble de sources, que le veilleur contrôlera pour en extraire les nouvelles informations pertinentes. Dans la phase de sourcing, c’est à dire lors de la recherche des différentes sources d’informations, outre les sources de type humaines ou pages web, il est possible d’y lister des bases de données, c’est à dire des ensembles structurés de contenus.
Les moteurs de recherche généralistes constituent le moyen le plus simple et populaire pour effectuer des recherches. Les bases de données proposent du contenu peu ou pas référencé, alors que celles-ci existent depuis plus longtemps et sont encore largement utilisées notamment par un public de chercheurs.
Leur point fort est avant tout la fiabilité et qualité des contenus validés, que l’on peut opposer aux résultats aléatoires des moteurs de recherche classiques. Leur structuration permet également une grande finesse d’interrogation, très appréciable pour la veille stratégique.
Les bases de données permettent de suivre l’actualité d’un domaine d’activité spécifique, de détecter les travaux des chercheurs ou encore les pistes d’innovation… On peut y trouver monographies, périodiques, références bibliographiques ou encore des images, en accès ouvert mais le plus souvent payant (abonnement ou paiement à la lecture).
Les typologies des bases de données en veille stratégique
On retrouve une multitude de bases de données accessibles sur internet, chacune ayant sa propre spécificité. Les veilleurs peuvent choisir d’effectuer :
- La veille technologique (Espacenet, ScienceDirect…)
- La surveillance réglementaire (Légifrance, Eur Lex…)
- La veille financière (Factiva Sociétés, Bloomberg…)
- Etc.
On peut les regrouper en différentes typologies :
Les plateformes d’éditeurs : Regroupent l’ensemble des publications d’un éditeur ou organisme spécifique, en accès ouvert, mais la plupart du temps payant
Les bases de données bibliographiques : Regroupent un ensemble de références de documents, dont l’accès renvoie vers les sites des éditeurs
Les moteurs de recherche spécialisés : N’indexent que les documents scientifiques du domaine, à la différence des moteurs classiques
Automatiser le processus de récolte des informations
En amont de la recherche, il convient de préparer ses requêtes. En effet, plus complexes qu’un moteur de recherche classique, les possibilités d’interrogations sont nombreuses. Il faut idéalement combiner les recherches sémantiques (choix des mots-clés, traductions éventuelles…) et les équations booléennes pour réduire le bruit.
Authentification
Certaines bases de données nécessitent une authentification de la part de l’internaute. Cela permet d’accéder à des ressources payantes accessibles aux seuls abonnés, ou à des sessions privées permettant d’enregistrer ses données, comme l’historique des recherches.
KB Crawl dispose d’un module permettant d’enregistrer des procédures afin de les reproduire : le MacroRecorder. Il simule les procédures de recherche sur un formulaire dynamique ou les étapes permettant d’utiliser les logins et mots de passe. Il permet ainsi d’accéder et de monitorer du contenu non accessible sans ces procédures, tels que des documents issus de bases de données fermées. Grâce au MacroRecorder, l’action de connexion est rendue automatique dans KB Crawl.
Mise en place d’alertes
La plupart des services permettent la création et l’abonnement à des systèmes d’alertes. Ces alertes peuvent être de type thématique ou mots-clés sur l’ensemble des champs d’interrogation. Elles se font par l’envoi d’emails, ou génération de flux RSS, selon une configuration personnalisée (fréquence d’envoi, format…). L’utilisateur est prévenu lorsqu’un nouveau contenu répond à une requête spécifique.
Suivi d’une recherche avancée
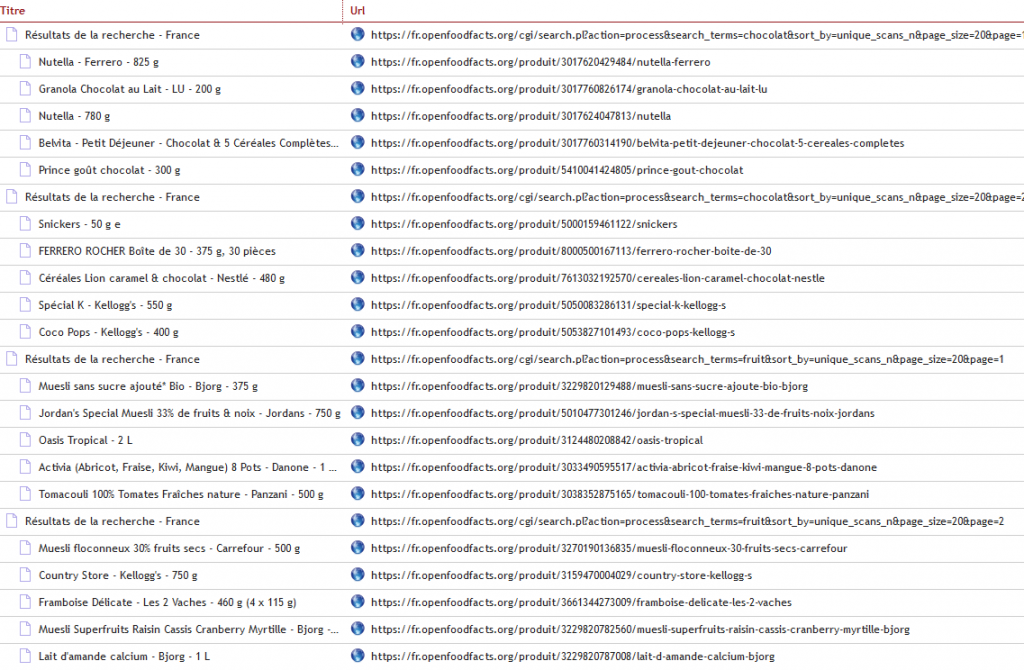
Lorsqu’un utilisateur saisit ses critères de recherche dans le formulaire d’une base de données, une page de résultats « dynamique » est générée.
Ci-après, une recherche sur les documents portant sur les congés payés du 25/05/2015 au 18/10/2018 :
Grâce au module DataDriven de KB Crawl, il est possible de jouer sur les éléments de cette URL afin d’effectuer plusieurs surveillances complexes d’une source. Pour ce faire, on remplace des parties variables d’une URL par une liste de valeurs prédéfinies (le nombre de pages à surveiller, les différents mots-clés à utiliser, les dates de début et de fin des publications…).
Structurer les résultats de recherche
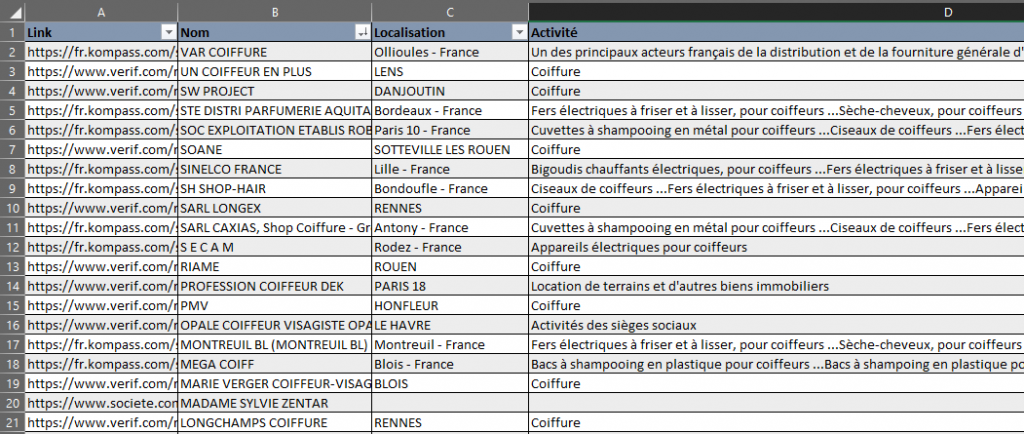
Pour un veilleur, les informations récoltées par le biais d’outils sont massives. Le Mapper de KB Crawl permet de structurer les données collectées issues de plusieurs sources web. On les retrouve dans une même colonne d’un tableau. Les informations sont découpées et classées, le veilleur peut alors les sélectionner ou les comparer, selon ses propres critères. Ce tableau s’alimente automatiquement selon la configuration de la périodicité.
Conclusion
Du fait de leurs interfaces et langages d’interrogation parfois complexes, les bases de données peuvent engendrer quelques difficultés pour les novices. Cependant, la maitrise de leur fonctionnement s’avère riche en valeur ajoutée. Ces sources d’informations ont encore de longues années devant elles, notamment grâce au mouvement du libre accès au contenu de qualité accessible via des bases de données.
À voir aussi
Le knowledge management : une dynamique d’innovation

Le knowledge management, vous connaissez peut-être ? Cette démarche managériale, apparue il y a peu,…
Lire l'article